· software testing · 8 min read
5 Testing Practices you should have in your CI / CD Pipeline
Nobody wants bugs in their apps, it could cause your company to lose millions of dollars. Adding these 5 testing practices can prevent it from happening to you.

Neciu Dan
Hi there, it's Dan, a technical co-founder of an ed-tech startup, host of Señors at Scale - a podcast for Senior Engineers, Organizer of ReactJS Barcelona meetup, international speaker and Staff Software Engineer, I'm here to share insights on combining
technology and education to solve real problems.
I write about startup challenges, tech innovations, and the Frontend Development.
Subscribe to join me on this journey of transforming education through technology. Want to discuss
Tech, Frontend or Startup life? Let's connect.

Let me tell you a story…
When I joined my current company, I received a pretty big shock. Out of the 500 engineers employed in three different tech hubs, we had a total of zero QA engineers employed.
For me, this was an entirely new concept, I moved from my previous company which had either one or two dedicated QA inside a Scrum Development team to ZERO.
I was used to having a fellow teammate go through my branch and add automated tests, API tests, or manually test it for various edge cases and business flows.
Without that person, what was I gonna do? During the onboarding we received clear instructions that we are supposed to follow the Testing Pyramid:
- Write a lot of unit tests
- Write some integration tests
- If the feature is important enough write an E2E test to cover the user’s journey.
- Manually test the feature.
And for my first ever task in the team, I was supposed to change something or another in the Sign-Up Dialog (A pretty important part of the application)
After I finished with the task at hand, I refactored a little bit to make the code cleaner, and I followed the testing pyramid.
- I wrote unit tests
- I wrote integration tests
- I wrote an e2e test
After that, I, of course, manually tested the feature with multiple edge cases.
 And the end result? I broke the CSS in almost ALL the dialogs in the application. And of course, as luck would have it, the dialog I was working on did not have this problem — it was great.
And the end result? I broke the CSS in almost ALL the dialogs in the application. And of course, as luck would have it, the dialog I was working on did not have this problem — it was great.
So we realized, pretty early in my tenure, that the testing pyramid was not working.
We decided to integrate more checks into our CI / CD pipeline to make sure that new joiners, like myself, would not break production as easily.
But it won’t stop developers from dropping the SEO rank of the application, by increasing the Core Web Vitals. For that we need to have Performance tests in place.
Performance Tests

There is a clear correlation between better Performance and Conversion Rate. And it makes sense, the faster your application loads, the sooner your users can interact with it and buy stuff.
Google takes this further and increases the SEO Rank for websites with better Performance. And it ranks performance based on these 3 metrics.
- FID (First Input Delay)
- LCP (Largest Contentful Paint)
- CLS (Cumulative Layout Shift)
I am not going to go into details about each of these metrics, but you can read all about them in the official documentation from Google.
What we care about is making sure we don’t degrade these metrics when we release a feature.
To accomplish this we are using the recommended tool, Lighthouse CI (It is being maintained by core google members)
Once you integrated the CI library into your pipeline, writing the performance tests is pretty straightforward.
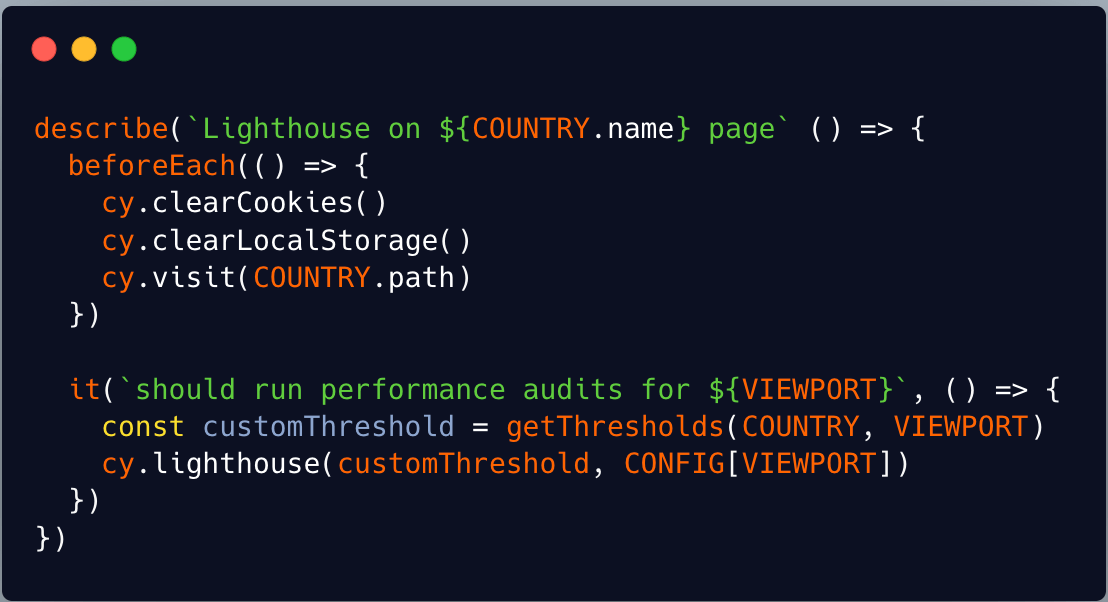
You basically care about only one command: cy.lighthouse() which runs the performance checks using the cypress library.
It boots the app in a browser, goes to the specified link, and compares the performance results to your thresholds — if the result is above the PR is not allowed to be merged.
These kinds of tests are what we call Lazy Tests. You write them once and forget about them, you don’t have to actively maintain them, or write a lot of them for each new feature.
Mutation Tests

And speaking of tests that we have to write a lot of… Unit tests have been here for a while.
They are at the bottom of the old-school pyramid. Considered the most important, because they are fast to run and cheap to write. (Which may no longer be the case in today’s Cloud Run Infrastructure)
But how do we make sure, that the most important piece of our testing infrastructure, is behaving as expected?
What if some of our tests are false positives? They are showing in our terminal and CI as green but are either skipped or worse: they are written badly and are not testing the result of the function under test.
Mutation Testing is the solution to our problem. And they work a little differently than normal tests. Usually, you would test that something works as expected, but mutation testing tests that something fails when it’s supposed to.
Let’s think about a simple sum function.
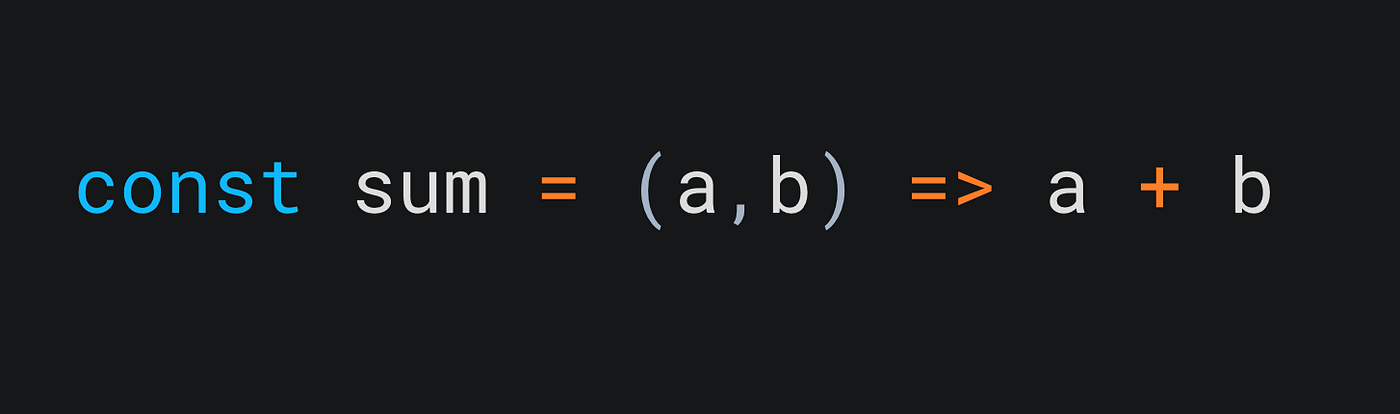
A mutation testing library, would go through this function, analyze the AST and find all the places where it can mutate your function.
For example, it locates the + operator, and it can change it to different operators like minus, multiplication, etc.
Then the library runs all the tests of this function, and because it changed the operator it expects at least one test to fail. If all of them pass, that means your Mutation Test is kept alive, and you have a bad test suite on your hands.
You can inspect the mutation later, debug and improve your code.
Rinse and repeat until you are satisfied with your Unit Tests and because running Mutation Tests is Expensive, you don’t have to add it to your CI pipeline, but can have an async process that does this every other month, to check the integrity of your Unit tests.
Visual Tests
Remember my story from the beginning of the article? Well, that definitely would not have happened if we had Visual Tests in place.
As the name implies, these tests make sure that visually everything is in order with your pages.
You can write a test for each type of page you have, and the library you use would boot up that page and take a screenshot. It will then compare that image with the image from the master branch, and ask you if the changes it finds are intentional or mistakes.
With Visual Tests integrated into your CI pipeline, you will no longer be afraid to touch general components because you might break design in different pages.
They give you the most confidence when it is about the CSS part of the application.
The downside of Visual Tests though is that it does not do that well when interactivity is involved.
If you had to click a button or scroll to the bottom of the page, introducing interactivity also increases flakiness.
Feature Tests
Feature Tests are the backbone of development these days. Adding Integration tests to your application is no longer a best practice because try as you might simulate a Frontend Application the best result is always achieved when you are testing like a real user.
Integrating different components together and testing the result in a terminal is not what we actually want, these are basically Unit Tests with extra steps (like mocking, stubbing, etc.)
We want our component to be booted in a browser, in isolation, and to interact with it as a user would.
This is achieved with Component Testing. The library of your choice starts a Single Page Application with just your component. And you can see what a real user is seeing.
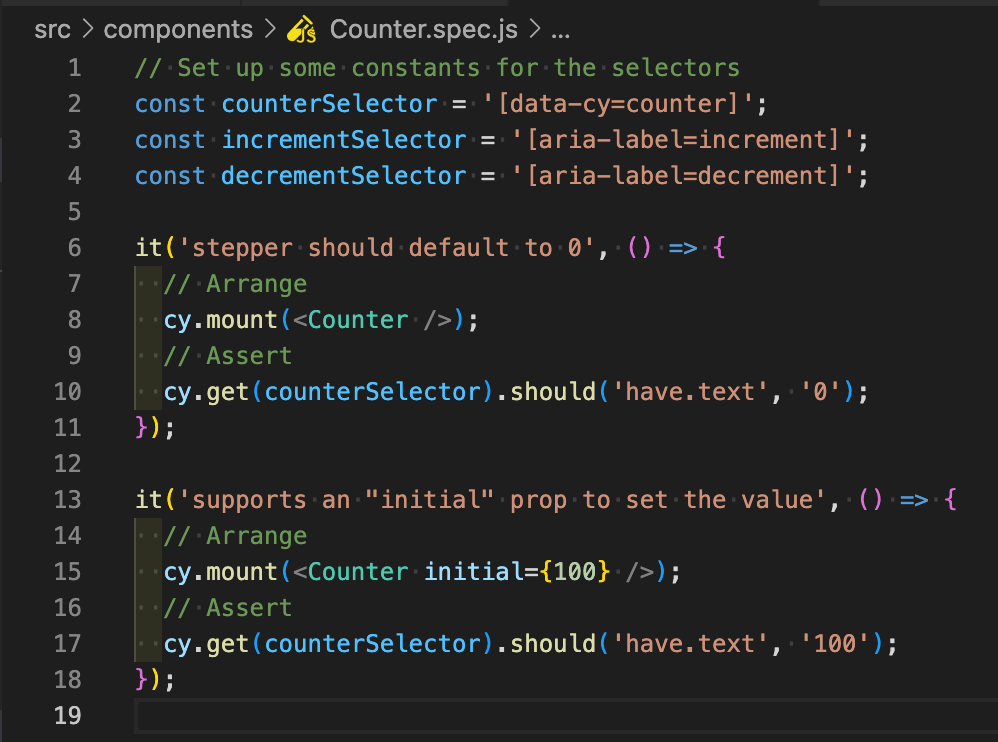
You can mount your component with different props, or no props at all, and test the default behavior.
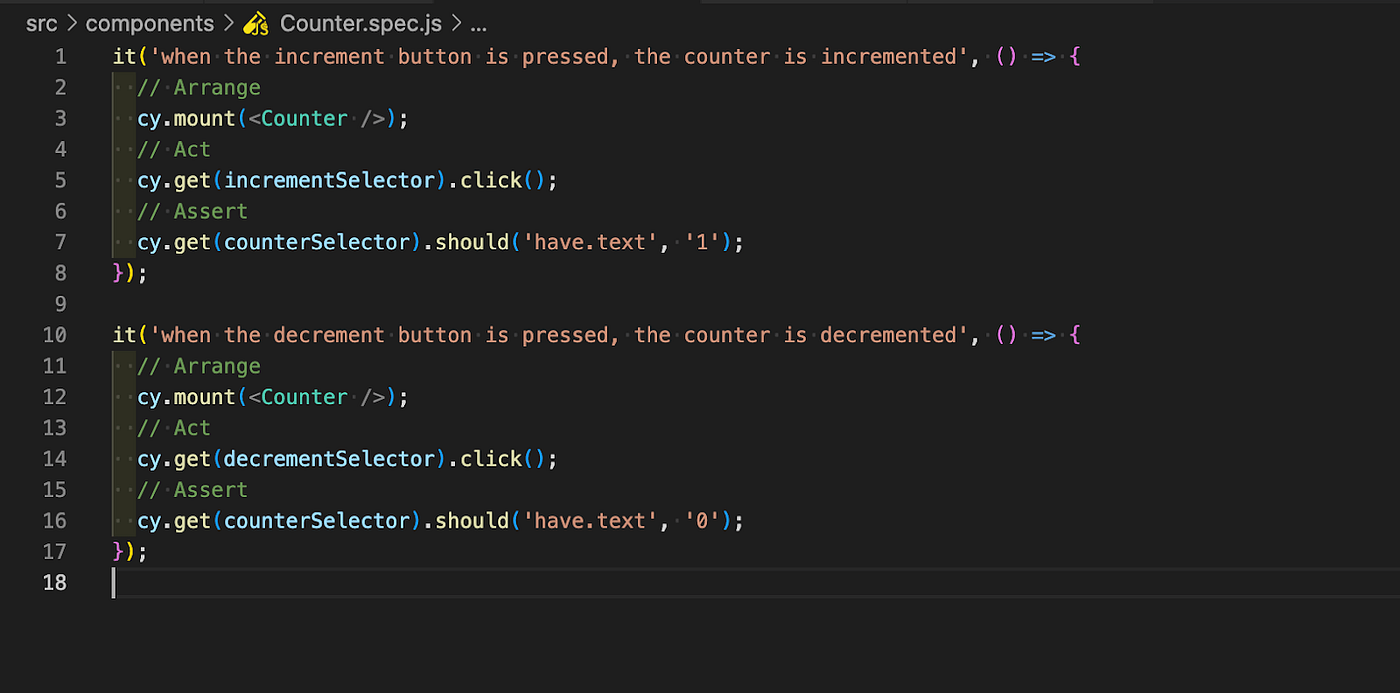
And then interact with your component as much as you want, while seeing the result in the browser.
This is also a good way to develop your component if you like writing TDD.
You don’t have to start the entire project just to see your small component in action, you can take advantage of the Component testing library and see it there.
Taking one step further, after your component has been tested in isolation you can also add an E2E test if your component is part of an important user journey.
Take care with E2E tests though, usually, they bring with them a lot of problems:
- They are slow
- They rely on backend Services to dynamically render content
- The API can have more significant latencies than the E2E library timeout period.
- You are most definitely testing multiple times the same section of a user’s journey.
We had all these problems and more, and applied some practices to at least reduce the amount of flakiness:
- We run our E2E test suits in parallel, here is a good article on how to achieve this.
- We implemented Skip Functionality in our tests by mocking cookies or by URL parameters. Example: ?SKIP_LOGIN_FUNCTIONALITY=true, which simulates a logged-in User (Only on testing env).
- We mocked our entire API by creating our own mock server that records the live response. You can read more about it, here.
You may think that mocking the entire backend may defeat the purpose of an E2E test. But we have strong consistencies in place, by taking advantage of Contract Testing.
Contract Tests
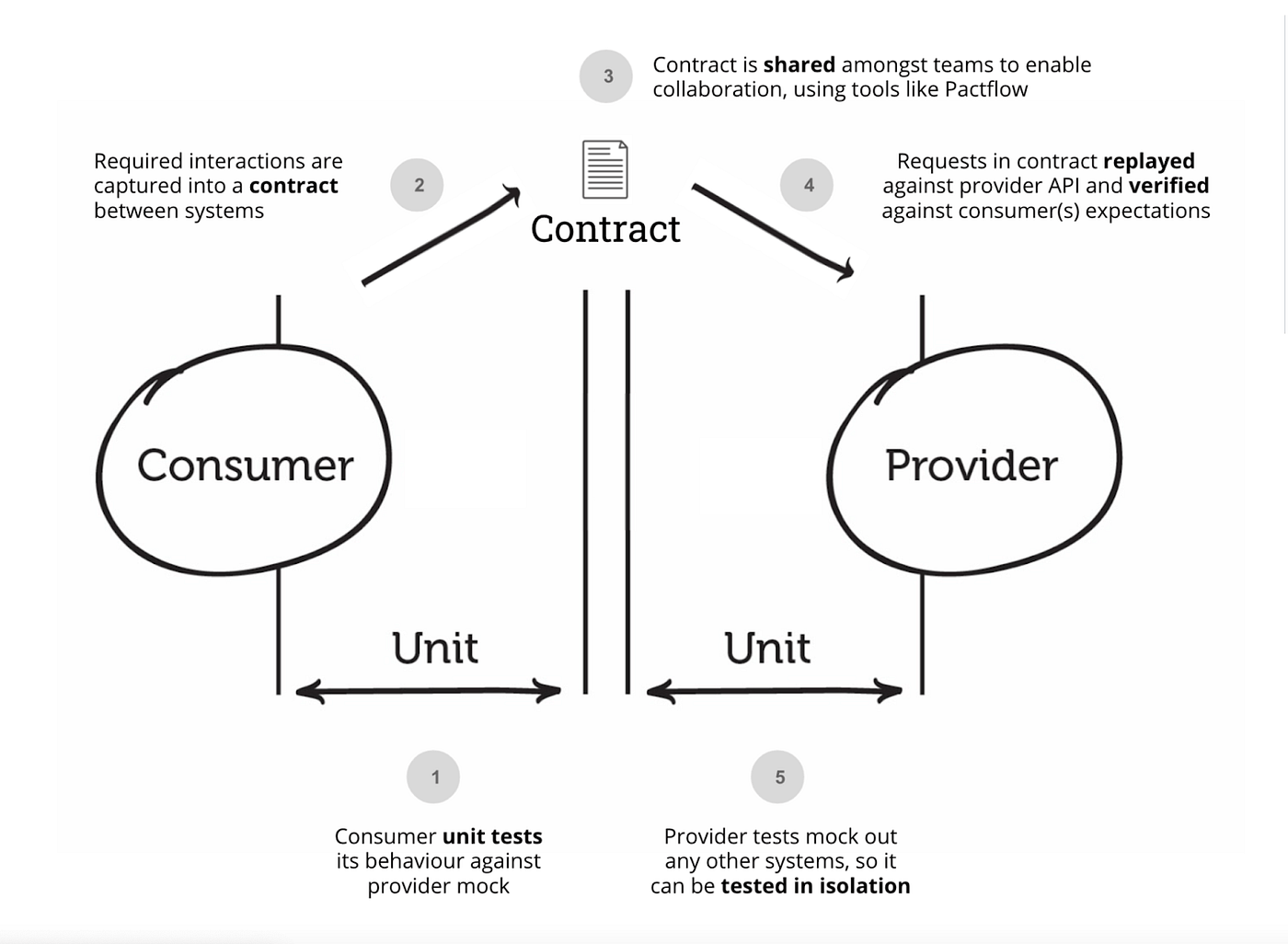
We found that the most common cause for all our outages was when the API response was different than the front-end application expected.
Usually, this error happened when a calculation in another micro-service fails and the gateway either returns undefined or skips the key in the response entirely.
Now the frontend application, the consumer of the data, declares a contract and says in every endpoint what response it expects and of what values and more importantly what type each value has to be. Some values can still be nullable of course.
You also declare in your contract, the services you are consuming, in case you have multiple APIs or you, are a backend Service consuming multiple micro-services.
The Contract is then saved in the testing library that you use, we chose PACT, and for every backend PR, it runs that output of the provider against that Contract. If it fails to respect the contract, the PR is blocked.

Discover more from The Neciu Dan Newsletter
A weekly column on Tech & Education, startup building and occasional hot takes.
Over 1,000 subscribers



